后端学习笔记
SpringBoot
Bean:Spring Boot中的Bean是指由Spring容器管理的对象。这些Bean通常是应用程序中的各种组件,如服务、存储库、配置类等,它们由Spring容器进行创建、配置和管理。
在Spring Boot应用程序中,可以通过在类上添加注解(如@Component、@Service、@Repository、@Controller等)来将一个类标记为一个Bean。Spring Boot会自动扫描这些注解,并在启动时将这些类实例化为Bean,然后将它们放入应用程序的上下文中,以便能够进行依赖注入和其他操作。
总结: 在Spring Boot中,Bean是由Spring容器管理的对象,通过注解标记的类会被Spring容器实例化并放入应用程序上下文中,以便进行依赖注入和其他操作。
注解
MVC:Model+View+Controller
1. 控制器Controller
1. 路由映射
- @RequestMapping
- Method匹配也可以使用@GetMapping、@PostMapping等注解代替
2. 参数传递
- @RequestParam:将请求参数绑定到控制器的方法参数上,接收的参数来自 HTTP请求体或请求url的QueryString,当请求的参数名称与Controller的业务 方法参数名称一致时,@RequestParam可以省略
- @PathVaraible:用来处理动态的URL,URL的值可以作为控制器中处理方法 的参数
- @RequestBody:接收的参数是来自requestBody中,即请求体。一般用于处理 非 Content-Type: application/x-www-form-urlencoded编码格式的数据, 比如:
application/json、application/xml等类型的数据
3. 数据响应
3.1 静态资源访问
使用IDEA创建Spring Boot项目,会默认创建出classpath:/static/目录,静态 资源一般放在这个目录下即可。
如果默认的静态资源过滤策略不能满足开发需求,也可以自定义静态资源过滤 策略。
在application.properties中直接定义过滤规则和静态资源位置:
spring.mvc.static-path-pattern=/static/**
spring.web.resources.static-locations=classpath:/static/过滤规则为/static/**,静态资源位置为classpath:/static/
3.2 SpringBoot实现文件上传功能
Spring Boot工程嵌入的tomcat限制了请求的文件大小,每个文件的配置最大 为1Mb,单次请求的文件的总数不能大于10Mb。
要更改这个默认值需要在配置文件(如application.properties)中加入两个配 置
spring.servlet.multipart.max-file-size=10MB
spring.servlet.multipart.max-request-size=10MB3.3 拦截器
拦截器在Web系统中非常常见,对于某些全局统一的操作,我们可以把它提取 到拦截器中实现。总结起来,拦截器大致有以下几种使用场景:
权限检查:如登录检测,进入处理程序检测是否登录,如果没有,则直接返回 登录页面。
性能监控:有时系统在某段时间莫名其妙很慢,可以通过拦截器在进入处理程 序之前记录开始时间,在处理完后记录结束时间,从而得到该请求的处理时间
通用行为:读取cookie得到用户信息并将用户对象放入请求,从而方便后续流 程使用,还有提取Locale、Theme信息等,只要是多个处理程序都需要的,即 可使用拦截器实现。
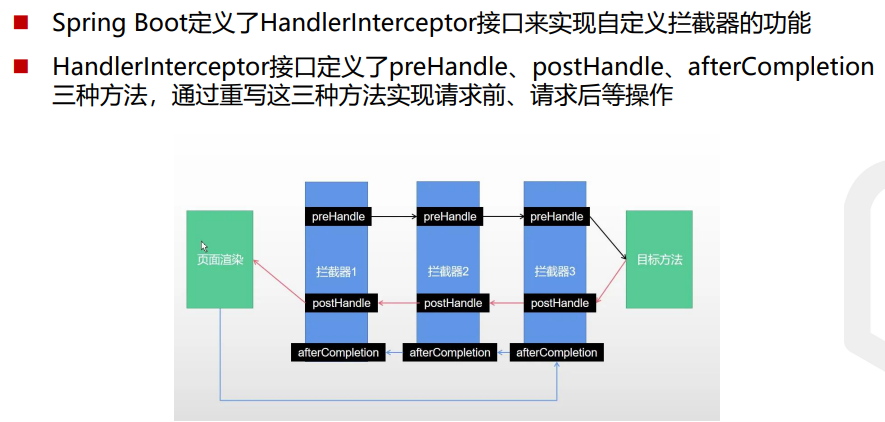
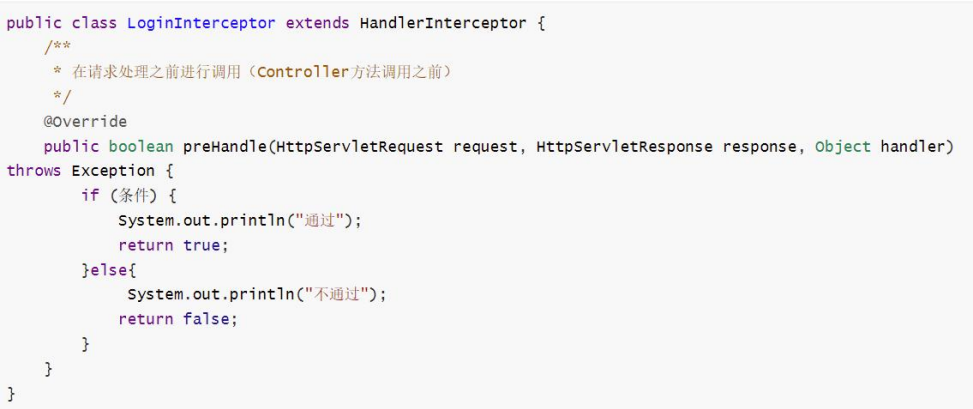
- 拦截器定义
- 拦截器注册

2. Swagger
什么是Swagger
Swagger是一个规范和完整的框架,用于生成、描述、调用和可视化RESTful风 格的Web服务,是非常流行的API表达工具。
Swagger能够自动生成完善的RESTful API文档,,同时并根据后台代码的修改 同步更新,同时提供完整的测试页面来调试API。
使用Swagger自动生成Web API文档
在Spring Boot项目中集成Swagger同样非常简单,只需在项目中引入 springfox-swagger2和springfox-swagger-ui依赖即可
配置Swagger
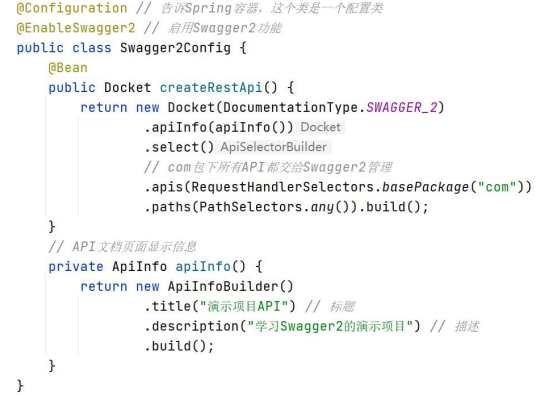
注意事项
Spring Boot 2.6.X后与Swagger有版本冲突问题,需要在 application.properties中加入以下配置:
spring.mvc.pathmatch.matching-strategy=ant_path_matcher使用Swagger进行接口测试
启动项目访问 http://127.0.0.1:8080/swagger-ui.html ,即可打开自动生成的 可视化测试页面
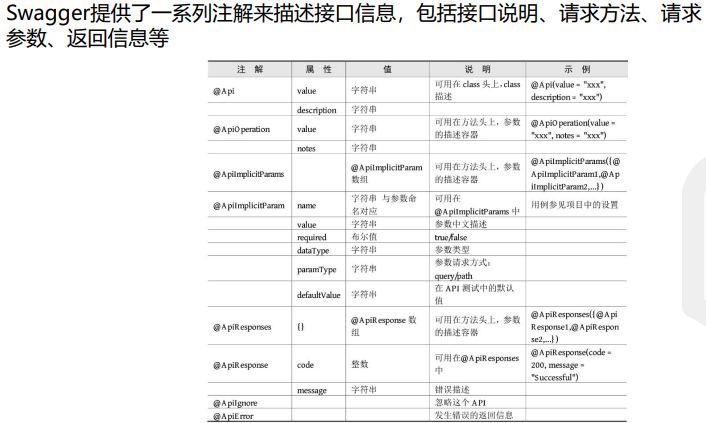
Swagger常用注解
开发环境热部署
- 在pom.xml配置文件中添加dev-tools依赖
使用optional=true表示依赖不会传递,即该项目依赖devtools;其他项目如 果引入此项目生成的JAR包,则不会包含devtools
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>- 在application.properties中配置devtools
添加如下代码:
// 热部署生效
spring.devtools.restart.enabled=true
// 设置重启目录
spring.devtools.restart.additional-paths=src/main/java
// 设置classpath目录下的WEB-INF文件夹内容修改下不重启
spring.devtools.restart.exclude=static/**- IDEA设置
- 打开Settings页面,在左边的菜单栏依次找到 Build,Execution,Deployment→Compile,勾选Build project automatically
- 新版本IDEA:在Setting页面,在左边的菜单栏找到Advanced ,勾选 Allow auto-make to start even if developed application is currently running复选框
- 老版本IDEA:按Ctrl+Shift+Alt+/快捷键调出Maintenance页面,单击Registry,勾选compile.automake.allow.when.app.running复选框。
- 做完这两步配置之后,若开发者再次在IntelliJ IDEA中修改代码,则项目会自动 重启
- 系统配置
项目创建成功后会默认在resources目录下生成application.properties文件。 该文件包含Spring Boot项目的全局配置
Mybatis
调用XML文件中的SQL命令
在Spring Boot项目中,针对数据库的增删改查操作通常使用MyBatis等持久化框架来管理。而MyBatis通常会使用XML文件来封装SQL语句。你可以通过以下步骤来调用XML文件中的SQL命令:
- 定义Mapper接口: 首先,你需要定义一个Mapper接口,用于声明要调用的SQL语句。Mapper接口中的方法名称和XML文件中的SQL语句的ID相对应。
public interface UserMapper {
User findById(Long id); // 方法名对应XML中的SQL语句的ID
}- 编写XML文件: 接下来,你需要编写一个XML文件,用于定义SQL语句。在XML文件中,你可以定义增删改查等各种操作的SQL语句,并通过
<select>、<insert>、<update>、<delete>等标签来标识不同类型的SQL操作。
<!-- UserMapper.xml -->
<mapper namespace="com.example.mapper.UserMapper">
<select id="findById" resultType="com.example.entity.User">
SELECT * FROM users WHERE id = #{id}
</select>
</mapper>- 配置Mapper接口和XML文件: 在Spring Boot的配置文件中,你需要配置MyBatis来扫描Mapper接口和XML文件,并将它们关联起来。
# application.yaml
mybatis:
mapper-locations: classpath:com/example/mapper/*.xml- 调用Mapper接口: 最后,在需要使用SQL语句的地方,你可以注入Mapper接口的实例,并调用接口中定义的方法来执行相应的SQL操作。
@Autowired
private UserMapper userMapper;
public User findUserById(Long id) {
return userMapper.findById(id);
}通过以上步骤,你就可以在代码中调用XML文件中定义的SQL命令了。在实际应用中,你可以根据需要编写更多的SQL语句,并在Mapper接口中定义对应的方法,从而实现各种数据库操作。
常用用法和设置
MyBatis 是一个优秀的持久层框架,在开发过程中常用的用法和设置有很多,以下列举了一些常见的用法和设置:
- XML映射文件: 使用 XML 文件来定义 SQL 映射,其中包含了 SQL 语句以及参数映射、结果映射等信息。
<mapper namespace="com.example.mapper.UserMapper">
<select id="findById" resultType="com.example.entity.User">
SELECT * FROM users WHERE id = #{id}
</select>
</mapper>- 注解方式: 除了 XML 文件外,还可以使用注解的方式来定义 SQL 映射,通过在方法上添加注解的方式来定义 SQL 语句。
@Mapper
public interface UserMapper {
@Select("SELECT * FROM users WHERE id = #{id}")
User findById(Long id);
}- 动态 SQL: MyBatis 提供了一套强大的动态 SQL 功能,可以在 SQL 中进行条件判断、循环等操作。
<select id="findByCondition" resultType="com.example.entity.User">
SELECT * FROM users
<where>
<if test="name != null and name != ''">
AND name = #{name}
</if>
<if test="age != null">
AND age = #{age}
</if>
</where>
</select>- 参数映射: MyBatis 支持多种参数映射方式,包括单个参数、多个参数、Map 参数、对象参数等。
<select id="findByCondition" resultType="com.example.entity.User">
SELECT * FROM users WHERE name = #{name} AND age = #{age}
</select>- 结果映射: MyBatis 支持将查询结果映射为 Java 对象,可以通过属性名、别名、构造函数等方式进行结果映射。
<resultMap id="userResultMap" type="com.example.entity.User">
<id property="id" column="user_id"/>
<result property="name" column="user_name"/>
<result property="age" column="user_age"/>
</resultMap>- 缓存: MyBatis 支持一级缓存和二级缓存,可以提高查询性能。
<cache eviction="LRU" flushInterval="60000" size="512" readOnly="true"/>- 插件: MyBatis 支持自定义插件,在 SQL 执行前后进行一些额外的操作,如日志记录、性能监控等。
@Intercepts({
@Signature(type = Executor.class, method = "update", args = {MappedStatement.class, Object.class})
})
public class ExamplePlugin implements Interceptor {
// 实现拦截逻辑
}- 动态数据源: MyBatis 支持动态切换数据源,可以根据不同的场景选择不同的数据源。
public class DynamicDataSource extends AbstractRoutingDataSource {
// 实现动态数据源的切换逻辑
}这些是 MyBatis 开发过程中常用的一些用法和设置,能够帮助开发人员更加灵活地使用 MyBatis 来操作数据库。
IDEA常用快捷键
1. 快速生成基本函数
在实体类前使用lombok提供的注解@Data可以快速生成构造函数和各属性的getter和setter方法
不需要手动在代码中写出构造、getter、setter函数
但是如果自定义构造、getter、setter函数则需要重写
生成getter、构造函数、重写toString函数的快捷键
在IntelliJ IDEA中,可以使用以下快捷键快速生成构造方法、getter方法等:
生成构造方法: 在类的任何位置,例如类的开头或者类的内部,输入
Alt + Insert(Windows/Linux)或者Cmd + N(Mac),然后选择 "Constructor",按下回车键。生成Getter和Setter方法: 同样在类的任何位置,输入
Alt + Insert(Windows/Linux)或者Cmd + N(Mac),然后选择 "Getter and Setter",按下回车键。
这些快捷键会在代码中自动生成相应的构造方法、getter和setter方法,并根据类中的字段进行适当的生成。
2. 快速生成main函数
在IntelliJ IDEA中,可以使用以下快捷键快速生成main方法:
- 在类的任何位置,例如类的开头或者类的内部,输入
psvm,然后按下Tab键。
这个快捷键会自动补全为:
public static void main(String[] args) {
}这样你就可以直接在main方法中编写代码了。
3. 快速生成多行注释
在IntelliJ IDEA中,快速生成多行注释的快捷键是 Ctrl + Shift + /(Windows/Linux)或者 Cmd + Shift + /(Mac)。这个快捷键会在当前光标位置插入多行注释。
如果想要在一个函数前添加多行注释并快速生成函数参数的多行注释,可以按照以下步骤:
- 将光标放置在函数定义的上方,即函数的第一行。
- 使用快捷键
Ctrl + Shift + /(Windows/Linux)或者Cmd + Shift + /(Mac)插入多行注释。 - 在多行注释中,使用
/**开始,并按下回车键。 - IntelliJ IDEA会自动生成多行注释的模板,并在模板中包含了函数的参数信息,可以根据需要修改参数说明。
- 编写完毕后,按下回车键即可。
这样就可以快速生成函数参数的多行注释了。
4. 快速生成print语句
输入sout,然后回车即可快速生成
开发知识
POLO及其转换-PO、DO、DTO、VO
概念
DTO(Data Transfer Object):数据传输对象,原先是为分布式提供粗粒度的数据实体,减少调用次数来提升性能和降低网络压力。
VO(view object):可视层对象,用于给前端显示的对象。(只传递有需要的参数以保障数据安全)
DO(Domain Object):领域对象,一般和数据中的表结构对应。
PO(Persistent Object):持久化对象,是一种 o/r 映射关系,可以看成是数据库表到java对象的映射。
概括
DTO:前端给后端传递的数据
VO:后端给前端传递的数据
DO:数据库表结构
PO:数据库表结构到JAVA的映射类
一般我们使用Mybatis建的类为PO,控制器接受到前端发来的参数为DTO,给前端发送的安全的数据为VO。如果数据类不做映射处理关系时PO=DO
知识点汇总
线程信息BaseContext:客户端发起的每一次请求都会是一个单独的线程,因此可以使用LocalThread存储每次线程中的信息
Web全局配置类WebMvcConfigration:在全局的配置类里进行注册(自定义方法),这些全局的配置包括:
自定拦截器——在拦截器中设置固定请求路径的jwt令牌校验
在进行jwt令牌校验时会解析当前登录用户的Token,获取登录用户ID并存储到LocalThread中进行保存,这样便可即时获取当前登录用户的ID
通过knife4j生成接口文档
设置静态资源映射
扩展消息转换器——对Java对象进行序列化处理(转换为JSON对象)
全局异常处理器Handler:针对后端报错而前端无法提示的情况,在后端设置异常处理器,对异常信息进行封装并传递给前端进行提示
jwt令牌校验拦截器JwtTokenAdminInterpreter:获取用户登录的令牌并校验,来决定是否放行
将后端返回对象统一封装在包result中,用泛型增强可用性,操作结果封装为Result类,分页查询结果封装为PageResult
将常量类存统一放在包constant下,分为MessageConstant、StatusConstant、PasswordConstant、JwtClaimsConstant等
将异常捕获信息统一放在包exception下
AOP
AOP(面向切面编程)是一种编程范例,它允许开发者定义和使用横切关注点(cross-cutting concerns)。
横切关注点是指影响应用程序多个部分的功能,比如日志记录、事务管理、性能统计等。这些功能与应用程序的核心业务逻辑部分相对独立,但却会影响到多个模块。
AOP 的主要思想是将这些横切关注点从原始模块中分离出来,形成切面(aspect)。切面是横切关注点的模块化体现,它可以定义在多个模块中共享的行为,并将这些行为与核心业务逻辑解耦。
AOP 的实现通常是通过在特定的切入点(join point)上执行特定的动作(advice)。切入点通常是在应用程序的执行过程中可以插入切面的地方,比如方法执行前、方法执行后等。而动作通常包括在切入点处执行的代码逻辑,比如日志记录、事务管理等。
Spring 框架提供了强大的 AOP 支持,可以通过声明式的方式来定义切面,并将其与应用程序的核心业务逻辑进行结合。
以下是一个简单的 Java AOP 示例,使用 Spring 框架的 AOP 功能来实现方法执行前后的日志记录:
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.After;
import org.aspectj.lang.ProceedingJoinPoint;
@Aspect
public class LoggingAspect {
@Before("execution(* com.example.service.*.*(..))")
public void logBefore() {
System.out.println("Before executing the method");
}
@After("execution(* com.example.service.*.*(..))")
public void logAfter() {
System.out.println("After executing the method");
}
}
public class MyService {
public void doSomething() {
// 执行核心业务逻辑
}
}在这个示例中,LoggingAspect 类定义了两个切面,分别在 MyService 类的方法执行前后执行日志记录的动作。
经典记录
递归查找孩子数量
/**
* TODO:求孩子节点数量
* @param parentId
* @return
*/
public int getChildrenNumberByParentId(int shipId, String parentId){
// children属性是类的数据成员,也就是说每定义一个对象,children属性都是空的
// 重新定义的类,并没有保存前面的children信息,麻了麻了,改Bug改了几百遍
// 所以每次查库然后返回的订阅表对象都是一个单独的变量,不会保存之前的信息,因此每次返回的children都是null,因为之前没有更新过children
// 吃了大亏这块!!!
List<SubScribeTable> currentRecord = subscribeMapper.getDefaultSubscriptionsByUserId(parentId);
// TODO:获取了整个订阅表,这块应该得删掉
List<SubScribeTable> subscribeTree = getSubscribeTreeByShipId(shipId);
if (currentRecord == null) {
return 0;
}
List<SubScribeTable> children = currentRecord.get(0).getChildren();
if (children == null || children.isEmpty()) {
return 0;
}
int count = children.size();
// 递归统计每个子记录的子记录数量,并累加到 count 中
for (SubScribeTable child : children) {
count += getChildrenNumberByParentId(child.getShipId(), child.getId());
}
return count;
}